기술과 솔루션




인공지능기술을 이용한 화학소재 개발 동향
작성자 : 편집부
2020-10-05 |
조회 : 9334
1. 서론
우리는 자라면서 경험을 쌓아가고 이를 기반으로 발전합니다. 실패와 성공을 경험해 보고 좌절도 겪으면서 경험을 축적하는 한편 이야기, 독서를 통해서 지식을 배웁니다. 축적된 경험과 습득된 지식은 머릿속에 데이터로 저장됩니다. 새로운 일이 생겼을 때 이렇게 쌓인 데이터를 바탕으로 이익, 윤리, 신뢰 등 참고하여 판단하고 행동합니다.
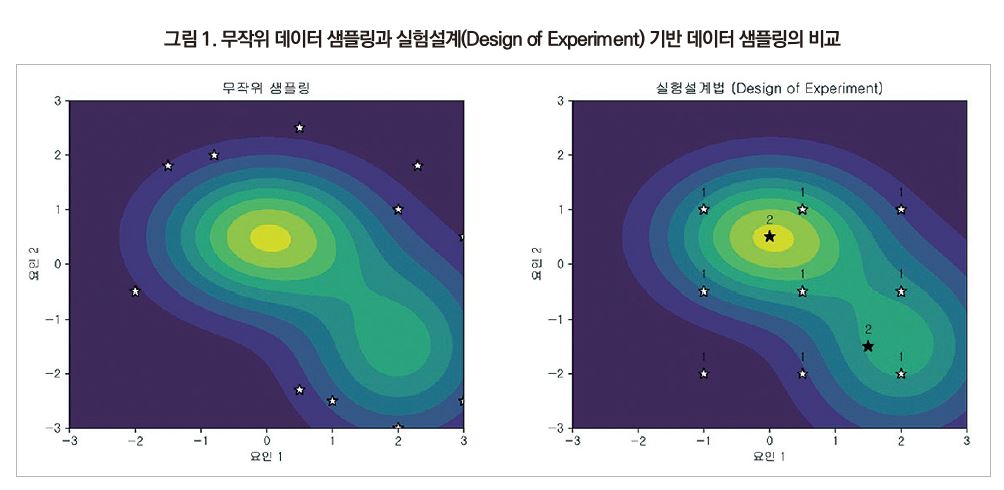
소재개발에서도 비슷한 방식이 적용됩니다. 그동안 소재개발은 경험과 지식에 근거한 실험, 이론, 컴퓨터를 이용한 전산모사 등을 통하여 이루어져 왔습니다. 개발 결과는 노트, 컴퓨터 파일, 논문, 특허, 기술자료 등의 가시적 형태와 무형의 전문지식으로 축적되어 있습니다. 새로운 소재를 개발할 때 그동안 주요 연구개발 방법인 실험, 전산 모사는 경비, 시간, 인력 등을 많이 투입해야 합니다. 그림 1에 소재개발에 활용되는 기술을 나타내었습니다.
2010년대 들어와서 미국, 일본 등 소재 선진국들은 미래산업 기반인 첨단소재개발의 효율을 높여 국가경쟁력을 유지하려는 노력을 기울이고 있습니다.
그동안 축적된 많은 소재 정보를 이용해 소재개발 경비와 시간을 줄이고자 국가적 지원이 활발히 이루어지고 있습니다. 미국의 Materials Genome Initiative(MGI)와 일본의 “Materials Research by Information and Integration” Initiative(Mi2i)가 대표적인 국가지원 프로그램입니다.
최근에 국내에서는 이세돌 기사와 구글 알파고의 대결 이후 인공지능 기술에 관심이 크게 늘고 있으며, 가전제품 등에 적용되어 일상생활에 많이 활용되고 있습니다.
인공지능 기술이란 인간의 지능과 같이 변화에 스스로 판단하여 대처할 수 있는 능력을 컴퓨터, 기계가 할 수 있도록 하는 기술을 말합니다. 인간이 경험과 지식 데이터에 기반하여 변화에 대응하는 것처럼 기계나 로봇들이 그동안 쌓아온 데이터를 분석하여 대응할 수 있습니다.
화학산업에도 인공지능 기술이 적용되기 시작하였습니다. 인공지능 기술들이 활용되는 분야는 공정 적용과 제품 설계입니다. 공정 적용 분야는 축적된 데이터를 분석하여 공정을 최적화하는 것과 이상징후를 알아내어 유지보수, 수리에 참고하는 것입니다. 기업에서 수행하는 공정은 장기간 비슷한 조건에서 운영되기 때문에 데이터 축적과 분석이 쉽습니다.
화학제품 개발에 적용되는 인공지능 기술은 제품 특성 예측과 제품 설계에 활용됩니다. 그동안 이 분야는 전문가가 축적한 전문지식에 의존해 왔습니다.
본 글에서는 화학소재 개발에 적용되는 인공지능 기술 개요와 적용사례를 설명하고자 합니다.
2. 인공지능(Artificial Intelligence, AI), 기계학습(Machine Learning, ML),
소재정보학(Material Informatics, MI) 이란?
AI란 앞서 설명한 바와 같이 사물(주로 기계)이 인간 지능과 같이 변화를 인지하고 판단하여 대처할 수 있는 능력을 말합니다. 과학기술정보통신부는 AI를 “인지, 학습 등 인간의 지적능력(지능)의 일부 또는 전체를 컴퓨터를 이용해 구현하는 지능”이라 정의했습니다.
AI는 넓은 의미로 사용되고 있습니다. 기계학습(ML)은 인공지능을 구사하기 위해 학습하는 것을 말합니다. 즉, 데이터를 분석, 추론해서 어떻게 할지를 결정하는 것입니다.
ML에서 중요한 것은 축적된 데이터, 분석능력, 추론(예측) 능력입니다. 데이터는 경험에 기반합니다. 데이터 분석능력은 지식과 조건에 달려 있습니다. 예측은 분석결과로부터 어떻게 대처해야 할지를 알아내는 것입니다.
ML은 AI를 수행하는 여러 기술 중 하나입니다. 알파고에 사용된 딥러닝(Deep Learning) 기술은 ML 중의 한 분야입니다. 표 1과 그림 2에 인공지능기술, 머신러닝, 딥러닝을 설명하여 나타내었습니다.
소재정보학(MI)은 특성과 같은 소재 정보를 분석하여 소재개발에 활용하는 것을 말합니다. 물성값처럼 숫자로 표시하기나 기술자료 같은 글자로 표현할 수도 있습니다. 본 글은 MI 분야에서 ML을 활용하는 사례를 살펴보고자 합니다.
2.1. 소재개발에 활용되는 ML 기술
ML을 이용한 소재개발은 데이터 확보, 데이터 보완 및 정제, 알고리즘을 활용한 분석, 분석결과의 검증 및 보완, 개발하고자 하는 소재의 특성 예측, 설계 적용 등의 순서로 진행됩니다. 그림 3에 ML을 이용한 소재개발 단계를 나타내었습니다.
1) 데이터 확보
ML의 첫 단계는 데이터를 모아 데이터베이스를 구축하는 것입니다. 맛있는 요리를 만들려면 재료가 좋아야 하듯이 ML을 잘하려면 데이터가 좋아야 합니다. 좋다는 의미는 데이터의 적합성과 신뢰성이 우수하고 양이 충분해야 한다는 것입니다. 즉 데이터가 활용하고자 하는 분야와 관련해야 하고 그 값을 믿을 수 있어야 합니다.
최근 빅데이터라는 말이 많이 사용되고 있습니다. 말 그대로 많은 양의 데이터를 의미합니다. 다수의 사람으로부터 얻은 건강, 구매 정보나 교통데이터는 양이 많은 경우가 대부분입니다. 이러한 빅데이터를 분석하는 다양한 프로그램들이 알려져 있고, 예측치 정확도도 나날이 높아가고 있습니다.
그러나 소재개발에 직접 사용할 수 있는 데이터는 많지 않습니다. 특정 소재개발에 필요한 데이터는 그 양이 더 적습니다. 일본에서는 이를 small data라 부릅니다. 우리는 경험이 많을수록 세상일에 잘 대처하듯이 데이터가 많아야 예측정확도를 높일 수 있는데, 소재개발에서는 공부할 수 있는 데이터가 부족합니다. 최근의 소재개발 ML 연구는 small data를 가지고 예측정확도를 높이는 방향으로 진행되고 있습니다. 2), 3)
2) Pruksawan, Sirawit; Lambard, Guillaume; Samitsu, Sadaki; Sodeyama, Keitaro; Naito, Masanobu. Prediction and optimization of epoxy adhesive strength from a small dataset through active learning. Science and Technology of Advanced Materials. 2019, 20, 1010-1021.
3) Wu, Stephen; Kondo, Yukiko; Kakimoto, Masa-aki; Yang, Bin; Yamada, Hironao; Kuwajima, Isao; Lambard, Guillaume; Hongo, Kenta; Xu, Yibin; Shiomi, Junichiro; Schick, Christoph; Morikawa, Junko; Yoshida, Ryo. npj Computational Materials. 2019. 5. 66
데이터베이스 구축에는 실제로 측정한 데이터와 컴퓨터로 시뮬레이션한 데이터가 사용되고 있습니다. 예전부터 현재까지 장기간에 걸쳐 실험을 해왔으며 측정된 데이터는 연구 노트, 논문, 특허 등에 있습니다.
이를 수집해 데이터베이스를 구축하는 것이 ML의 시작입니다. 이때 용어, 단위, 측정 방법 및 조건 등을 세심히 정리해서 데이터베이스를 구축해야 합니다.
쓸만한 데이터가 부족하면 데이터베이스를 구축하기 위해 새로 측정해야 합니다. 데이터를 생산해서 데이터베이스를 구축하는 과정은 시간과 예산이 많이 듭니다. 최근에는 컴퓨터 시뮬레이션 기술이 발달해서 양자역학 등의 이론을 기초로 하는 제일원리 모사나 분자동력학 기술 등을 사용하여 데이터를 생산하는 예도 많습니다.
화학소재 관련해서 여러 개의 데이터베이스가 알려져 있습니다. 이들 데이터베이스로부터 데이터를 가져오거나 자신의 데이터를 모아 직접 소재 데이터베이스를 구축할 수도 있습니다.
확보된 데이터는 정제하고 보완해야 합니다. 요리할 때 씻고 쓸모없는 것은 빼내고 먼지 등 더러운 불순물은 제거해서 깨끗한 요리 재료를 얻고 또 꼭 필요한 양념 등을 갖추는 과정이라 생각하면 됩니다.
2) 특징 추출(feature extraction)
데이터가 확보되면 컴퓨터가 데이터의 특성을 인식할 수 있도록 재료를 다듬어야 합니다. 소재개발에서 ML이란 input 데이터를 분석해서 형태, 패턴 등을 찾아내고 원하는 물성이나 구조를 예측하는 것입니다.
컴퓨터가 사용해 만들어 내는 output에 영향을 줄 수 있는 input 인자를 정해야 하며 이는 숫자로 정리되어야 합니다. 이런 input 인자를 descriptor, feature, fingerprint라고 부릅니다. 이 용어들은 논문 저자에 따라 의미에서 약간의 차이는 있지만 여기서는 이를 특징 (feature)로 통일해 부르겠습니다.
고분자 유리전이온도(Tg)를 예측하고자 할 때 전문가들은 Tg에 영향을 미치는 인자들을 추측할 수 있습니다. 분자구조식, 입체이성질체, 벤젠 같은 강직 구조 등 화학구조와 결정, 배향 같은 물리 구조 등 다양한 변수가 있습니다.
이와 같은 변수들을 단독 혹은 몇 가지가 결합한 것을 찾아내고 이를 숫자로 표현하는 것이 특징 추출과정입니다. 특징 추출은 소재 전문지식 (domain knowledge)을 가지고 있는 소재 전문가가 잘할 수 있습니다.
화학구조를 Feature로 나타내는 방법으로 simplified molecular-input line-entry system(SMILES)이 있습니다.
예를 들면 폴리스티렌의 경우 SMILES로 나타내면 다음과 같습니다.
3) 알고리즘 선택과 분석 수행
데이터를 정제하고 특징 선택한 값들을 사용하여 분석, 추론하는 기술이 알고리즘 적용기술입니다. 화학소재 개발에 필요한 알고리즘은 직접 프로그래밍도 가능하지만, 컴퓨터 과학자들이 이미 알고리즘을 개발해 제공하고 있으므로 이를 사용할 수도 있습니다.
소재개발 ML에 사용되는 알고리즘에는 y=f(x)로 표현할 수 있는 지도학습(super vised learning) 방법이 많이 쓰이고 있습니다. 이 방법은 input 값에 대하여 output 값이 있는 경우입니다. x값에 대하여 y값을 만족시키는 최적의 함수 f(x)를 찾아내어 새로운 x값이 주어졌을 때 y값을 예측하는 방법입니다.
직선 회귀법(linear regression)이 지도학습의 가장 대표적인 알고리즘입니다. 이 방법은 실제값과 예측값과의 차이 제곱을 최소화하는 방법입니다.
통상 선형회귀법에서 함수는 y=ax+b로 표현됩니다. 여기서 a, b는 상수입니다. 그림 5에 지도학습에 사용되는 여러 알고리즘은 나타내었습니다. 자세한 것은 문헌을 참조하시기 바랍니다.
ML 방법에는 지도학습 외에도 준 지도학습, 강화학습 등의 방법이 있으며, 각 방법에 여러 알고리즘이 있습니다.
소재개발에는 다양한 알고리즘들이 사용되고 있습니다. 자세한 것은 뒷부분에서 설명하였습니다.
알고리즘을 사용하여 데이터를 잘 표현할 수 있는 함수식을 찾을 수 있습니다. 직선 회귀법에서는 R2(R square, 결정계수) 값이 1에 가깝고, RMSE(root mean square error, 평균 제곱근 오차) 값이 작을수록 예측값이 함수식 선에 일치하는 정도, 즉 예측정확도가 높아집니다. 다양한 feature와 여러 알고리즘을 사용해서 실제 데이터와 예측 데이터를 분석한 후, 예측을 가장 정확하게 할 수 있는 feature와 알고리즘을 정하게 됩니다.
이 과정을 학습(training, 훈련)이라 합니다. 알고리즘이 선정되면 이를 카테고리 내의 다른 데이터에 적용해 보는 것이 일반적입니다. 이를 테스트라 부릅니다. 테스트를 통해서 알고리즘 사용 시 정확도를 더 자세히 파악할 수 있습니다.
개발에 사용되도록 정확도를 높이기 위해서는 추가 실험이 필요할 때가 많습니다. 이때는 실제로 개발하려는 소재와 유사한 조건을 갖도록 실험을 추가하여 데이터를 보강한 후 위의 과정을 다시 실시하는 것입니다. 이렇게 하여 좀 적합한 피처와 알고리즘 조건을 찾을 수 있으며, 이를 이용하여 개발 소재에 대한 특성을 더 정확히 예측할 수 있습니다.
데이터 수가 적은 small data일 때 예측정확도가 낮게 나오는 경우가 많습니다. 이때는 비슷한 형태를 보이는 다른 데이터를 이용하기도 합니다. 예를 들어 고분자의 열전도도에 관한 데이터는 매우 적기 때문에 충분히 학습할 수가 없습니다.
고분자 전문가들은 고분자 열전도도는 고분자의 화학구조, 특히 방향족 그룹에 영향을 많이 받는다고 알고 있습니다. 방향족 그룹에 영향을 많이 받는 고분자의 다른 특성으로 Tg가 있습니다.
Tg는 고분자 개발 시 주요 인자이므로 Tg에 관한 데이터는 매우 많습니다. Tg 데이터로 ML 연구를 한 후 이 함수를 열전도도도 예측에 사용하는 방법도 보고되어 있습니다. 이러한 방법을 전이학습(transfer learning)이라 합니다3).
4) ML 결과의 활용
소재 구조로부터 특성을 예측하는 것이 소재 ML 연구의 가장 흔한 일이지만, 역으로 원하는 특성을 가지는 소재를 설계할 수도 있습니다. 앞 방법을 전방예측(forward prediction)이라 하고 후자 방법을 후방예측(backward prediction)이라 합니다. 소재개발에서 중요한 부분이 소재를 설계하는 것이므로 후방예측이 중요하지만, 데이터가 많이 없으면 ML로 소재를 설계하기는 매우 어렵습니다.
그림 6에 일본 국립연구기관인 National Institute of Materials Science, NIMS)에서 수행한 전이학습과 후방예측 과정을 나타내었습니다. NIMS는 고분자 특성을 모은 데이터베이스 “PoLyInfo”를 구축해 오고 있습니다. 전 세계에 발표되는 논문 문헌으로부터 다양한 명칭, 구조, 특성치 등을 직접 연구자가 읽어서 데이터를 추출하여 데이터베이스를 구축하고 있습니다.
NIMS 연구자들은 고분자의 열전도도를 예측하고자 했으나 데이터가 부족해서 전이학습 방법을 사용했습니다3). 먼저 PoLyInfo 데이터베이스와 단량체 데이터 베이스인 “QM9”을 함께 사용해 전방예측으로 Tg와 Tm 예측하였으며, 이를 참고로 하여 후방예측을 위해 특정 Tg와 Tm값을 갖는 분자구조를 예측하는 ML을 연구했습니다. 알고리즘으로는 NIMS에서 개발한 “Bayesian Molecular Design”을 사용했습니다.
열특성 ML연구에서 선택된 feature(그림에서는 fingerprint로 표현)와 알고리즘 조건을 열전도도 데이터에 적용해 정확도를 알 수 있었습니다.
학습된 조건을 이용해 열전도도가 클 것으로 추천된 약 1,000개의 화학구조로부터 가공성, 합성 편의성을 참고로 하여 3가지 구조를 선정하고 이를 중합하였습니다. 제조된 고분자의 열전도도를 측정한 결과, 0.41W/mK의 높은 열전도도를 갖는 소재를 개발할 수 있었습니다.
2.2 구체적 ML 연구 예
1) 고분자 Tg 예측
고분자의 Tg를 예측하는 ML 과정을 예로 들겠습니다(그림 7 및 8). 첫 단계는 구조가 다른 다양한 고분자에 대한 Tg 데이터를 모으는 것입니다. 다음으로는 고분자의 화학구조, 물리구조 등을 참고로 하여 feature를 정하는 것입니다. 이 보고서에서는 feature를 fingerprint로 표현했습니다.
Fingerprint에는 각 고분자에 대해 M개까지 만들 수 있습니다. 모든 고분자가 M개의 feature를 다 갖고 있지는 않습니다. 다음으로 숫자로 표시된 fingerprint와 데이터에 있는 Tg 값을 이용하여 기계학습을 수행합니다(ML). 이때 fingerprint의 종류와 개수를 달리하면서 여러 알고리즘에 적용해 볼 수가 있습니다.
이후 얻은 예상값과 실제 데이터를 비교해서 정확도가 높은 fingerprint와 알고리즘을 정합니다. 마지막으로, 이를 이용하여 구조를 알고 있는 새 고분자의 Tg를 예측할 수 있습니다. 여기서 중요한 것이 fingerprint를 정하는 것입니다.
구체적으로 예를 들어 설명하겠습니다. 화학구조를 알고 있는 고분자 소재 데이터를 밀도함수이론(Density functional theory)에 근거한 컴퓨터 시뮬레이션으로 구한 특성(bandgap, dielectric constant, refractive index, atomization energy)과 문헌 혹은 직접 실험으로 구한 측정값(glass transition temperature, solubility parameter, density)의 7개 특성에 대한 데이터베이스를 구축했습니다. 고분자는 854개이고 H, C, N, O, S, F, Cl, Br, I의 9 원자 중에서 몇 가지로 이루어져 있습니다. 854개 고분자 모두가 7개 특성치를 다 가지고 있는 것은 아닙니다. Tg 데이터는 451개 고분자, 유전상수는 384개 고분자에 해당하는 데이터가 있습니다.
본 보고서에서는 fingerprint를 3개의 분류로 나누고, 그 개수를 달리하면서 ML 학습을 수행하였습니다.5) 3개 분류의 첫 번째는 작은 스케일인 원자 레벨을 고려하였습니다. 예를 들어 고분자 화학구조를 원자 3개로 이루어지는 atom triple 상태로 나누어 표기하는 것입니다(atomic level descriptor, A 그룹).
다음으로는 중간단계 스케일로서 QSPR(quantitative-structure property relationship)에 적용하는 것과 같이 방향족 그룹과 지방족 그룹 비율, 단일 결합을 하는 sp3 C의 비율 등으로 나타내는 것입니다(QSPR descriptor, Q 그룹). 마지막으로는 큰 스케일로서 분자 내의 ranch 그룹 길이, 강직한 방향족 사이 거리, 주쇄 길이 등으로 나타내는 것입니다(morphological descriptor, M 그룹).
5) Chiho Kim; Anand Chandrasekaran; Tran Doan Huan; Deya Das; Rampi Ramprasad; Journal of Physical Chemistry C. 2018, 122, 17575-17585.
고분자 연구자는 전문지식을 이용하여 A, Q, M그룹에서 다양한 fingerprint를 만들어 낼 수도 있고 각각 fingerprint를 조합할 수도 있습니다, 예를 들어 A1A2, AQ, QM, AQM 등과 같이하여 다양한 fingerprint를 만들 수 있습니다, Fingerprint를 생성하고 조합하는 것은 고분자 전문가 지식에 크게 좌우됩니다. 일반적으로 fingerprint 개수가 많아질수록 정확도를 높일 수 있지만, 복잡해져서 ML 학습이 어려워집니다.
그림 8(a)의 가장 오른쪽에 있는 그림에 나타낸 바와 같이 feature 수가 증가하면 에러가 줄지만, 일정 값 이상에서는 오히려 에러가 커지고 있습니다. 일정 값 이상으로 커지면 쓸모없는 값들이 포함되므로 정확도가 떨어질 수 있습니다. 최적 feature 수가 있음을 나타내고 있습니다. 최근에는 fingerprint를 선정해 주는 툴도 나와 있습니다.
그림 8(b, c, d, e)에 fingerprint에 따라 정확도가 영향을 받는 것을 나타내었습니다. A에서 108개, Q에서 99개, M에서 22개의 fingerprint를 정해서 여러 알고리즘에 적용해 보았습니다. 그림 8의 (b)는 A 그룹 feature만을 사용해서 예측한 Tg 결과이고, (c), (d)는 각각 AQ, AQM으로 feature를 조합해 더 많이 사용한 결과입니다.
이때 training은 854개 중 360개 고분자를 대상으로 하였으며, 91개 고분자를 사용하여 검증 test를 실시했습니다. Feature 수가 확대됨에 따라 예측정확도를 나타내는 R2 값이 1에 가까워지고 있고, test 시 편차를 나타내는 RMSE 값도 51K에서 33.6K로 작아지고 있음을 할 수 있습니다.
즉 feature를 AQM으로 확대하면 더 정확히 예측할 수 있습니다. 또한 학습(training)으로 구한 예측값보다 그 조건을 가지고 91개에 대해 검증 test 결과의 R2 값이 작음을 알 수 있습니다. 검증 test의 데이터는 학습 데이터와 달라졌기 때문에 예측정확도가 떨어지는 것입니다.
그림 8(e)은 최적 feature 수로 예측한 값을 보여주고 있습니다. 학습과 테스트의 정확도가 모두 높아졌고 편차도 크게 줄었습니다. 비슷한 방법으로 Tg 이외에 밴드갭, 유전상수, 굴절률, 밀도 등 다른 특성들도 예측할 수 있는 feature 종류 및 개수를 정할 수 있습니다. 발표 논문에 의하면, 최적 feature 개수는 굴절률은 19개로 작았고, atomic energy는 207개로 많았습니다.
2) 고무배합 데이터로부터 물성예측
한국화학연구원 화학소재소재은행은 2007년부터 플라스틱, 고무 등의 특성 데이터베이스를 구축해 오고 있습니다. 화학소재정보은행은 특히 용도별 고무 컴파운드의 조성비, 공정, 물성 정보 등을 실험을 통해 구축해 왔으며, 현재 배합 800건과 물성 15,500건이 있습니다. 고무배합 데이터베이스에는 고무 11종과 카본블랙, 실리카, 무기물 등 충전재가 있습니다.
고무 소재개발에서는 원료 고무, 충전재, 가황물 등 조성비와 공정조건 변수에 따라 고무 물성이 달라집니다. 구축된 고무배합 데이터베이스를 사용하여 ML 연구를 수행하였습니다.
데이터 전처리 과정을 통해 고무 컴파운드 및 물성의 이상치(outlier)를 제거하여 컴파운드 445종의 데이터를 준비하였습니다. 준비된 데이터는 7:3 비율로 학습과 테스트 셋으로 나누었으며, 가교 후 비중, 인장강도, 인장탄성률, 압축탄성률, 마모도의 물성을 예측하였습니다.
예측 모델은 머신러닝 알고리즘인 SVR(Support Vector Regression), RFR(Random Forest Regression), ETR(Extra-tree Regression)을 사용하였고, 모델마다 하이퍼-파라미터(Hyper-parameter) 최적화를 수행하였습니다. 평가는 테스트 셋의 R2(R-squared), RMSE(Root Mean Squared Error), MAE(Mean Absolute Error)를 사용하여 실시하였습니다.
SVR 모델의 하이퍼-파라미터에는 C(cost), gamma, epsilon이 있습니다. C는 데이터가 다른 분류에 놓이는 것을 어느 정도 허용하는 파라미터이며, gamma는 결정 경계의 곡률을 결정하는 파라미터입니다. C와 gamma는 모두 커지면 알고리즘의 복잡도가 증가하여 과대 적합(overfitting) 되고, 작을수록 복잡도는 낮아져 과소 적합(underfitting) 될 가능성이 큽니다.
RFR과 ETR 모델에는 n_estimators, max_leaf_nodes 등의 하이퍼-파라미터가 있습니다. n_estimators는 생성할 의사결정 나무 개수이며, 생성한 의사결정 나무 개수만큼 앙상블로 모델을 학습시키게 됩니다. Max_leaf_nodes는 최대 잎의 개수를 의미합니다. 모델마다 데이터에 적절한 하이퍼-파라미터를 찾아야 우수한 예측 모델을 만들 수 있습니다.
고무배합 데이터를 SVR 모델에 적용하여 물성의 최적화 하이퍼-파라미터를 측정하였습니다. 파단 인장강도에서는 C=1, gamma=0.008에서 최적화되었습니다(그림 9). RFR과 ETR 모델의 경우 n_estimators보다는 max_leaf_nodes에 의해 물성예측을 최적화하였습니다.
하이퍼-파라미터 최적화 조건에서 모델별로 비중, 인장강도, 인장탄성률 등의 5개 물성을 예측한 결과, 테스트 셋에서 예측 물성 평균 R2는 SVR 0.81, RFR 0.88, ETR 0.90이었습니다.
학습한 모델에서 학습 셋 대비 테스트 셋의 오차율은 SVR 9.23%, RFR 8.25%, ETR 7.72%이었습니다. 그림 10에 ML 모델별로 파단 인장강도 예측값을 비교하였습니다. 학습모델 중에 ETR이 R2 0.89, RMSE 2.31 값을 보여 가장 우수한 알고리즘으로 나타났습니다.
3) 능동학습을 이용한 접착제 개발
일본 NIMS 연구진은 ML을 활용하여 고성능 접착제 개발 연구를 하였습니다. 접착제는 주제, 경화제와 다양한 첨가제를 원료로 하고 온도, 압력 등의 성형조건에 따라 특성이 크게 달라집니다.
앞서 언급한 바와 같이 실험데이터 수는 small인 경우가 많습니다. 본 연구에서도 32개 적은 수의 조성에 대한 접착강도 데이터를 가지고 feature와 알고리즘을 1차로 정했습니다.
여기에 15개 조성의 실험을 추가해서 특성을 더 정확하게 예측할 수 있도록 feature와 알고리즘을 확정하였습니다. 이를 능동학습이라 합니다. 다음에 확정된 feature와 알고리즘을 사용하여 우수한 특성을 나타낼 수 있는 약 1,000개의 조성을 제안하고 그중에서 4개 조성을 실험하였습니다.
접착력 측정 결과 36MPa이라는 높은 접착강도를 나타내는 접착제 조성을 알 수 있었습니다. 만약 약 1,000개 조성에 대해 실험을 했다면 1년 이상의 긴 기간이 필요했겠지만, AI 능동학습을 통해 수일 만에 우수한 접착제 조성을 얻을 수 있었습니다(그림 11).
3.1 학술 동향
화학소재에 ML을 이용하여 특성을 예측하려는 연구가 최근 활발합니다. 유기 태양전지, OLED, 고분자 태양전지, 고에너지 소재, 고 굴절률 폴리이미드, 고 열전도성 고분자, drug-like 분자 등에 ML 연구 결과가 발표되었습니다. 전환효율, 유전상수, 밴드갭, 굴절률, 열전도도, HOMO/LUMO, biological 특성 등을 예측하기 위한 9개의 ML 연구결과를 표 2에 정리하였습니다.
사용된 데이터베이스로는 자체 구축한(self-build library) 경우가 많았으며, 데이터 크기는 수십 개의 스몰 데이터부터 수백만 개까지 큰 차이가 있습니다. 본 글에서 설명한 feature는 표 2의 representation column에 있는 내용으로 저자마다 표현을 다르게 사용하고 있습니다. 표 2의 제일 오른쪽 column에 보이는 바와 같이 알고리즘으로는 MLR, KRR, ANN, SVM, Bayesian model, DNN, RL 등 다양한 종류가 사용되고 있습니다.
소재개발은 원료, 공정, 특성, 응용 등 다양한 관점에서 연구가 진행됩니다. 소재개발을 위한 ML 연구에서 feature와 알고리즘 적용도 연구자 및 소재개발 특성에 따라 달라집니다. Domain Knowledge를 갖춘 소재 전문가와 데이터 과학자의 협력으로 최적 feature와 알고리즘을 알아낼 수 있습니다. 즉, 전문지식과 협력, 경험이 중요합니다.
3.2 일본 화학기업의 인공지능 활용
AI 기술에 관심을 두는 일본 화학기업들이 최근 급격히 늘고 있습니다. 공정 최적화, 이상징후 사전탐지, 품질관리 등 사례가 많으며 소재개발에도 활용되고 있습니다.
MI가 소재개발에 적용되는 주요 분야는 화학구조나 생산 레시피와 제품 특성 관계 데이터베이스를 구축하고 학습하는 것입니다. 개발 소재의 특성 예측이 첫 목표이지만, 역으로 원하는 특성을 가지는 소재 구조(레시피)를 추천할 수 있는 feature와 알고리즘을 구축합니다. 이를 통해 개발 경비를 줄이고 사업화 속도를 빠르게 하여 기업의 경쟁력을 높일 수 있습니다.
NEC 같은 IT 기업도 MI 연구를 활발히 하고 있습니다. NEC는 중앙연구소에서 열전 개발에 대한 MI 기술을 축적해 왔으며, 그 know-how와 데이터 인프라를 판매하고 있습니다. 데이터 인프라에는 실험데이터베이스, 데이터 가시화 툴, AI 분석 툴 등이 포함되어 있습니다
일본 기업들은 데이터 과학 인력확보에도 큰 노력을 기울이고 있습니다. 전문가뿐 아니라 일반 연구원 혹은 소속원 대부분이 데이터를 이해하고 쉽게 활용할 수 있는 능력 갖추기를 목표로 하는 기업들이 나타나고 있습니다.
표 3에 일본 기업들의 최근 MI 연구 및 활용 사례를 정리했습니다.
최근 인공지능 기술이 유행함에 따라 국내외 화학기업들 대부분이 MI에 관심이 있으나 생산이나 연구개발에 유용하게 활용하는 기업은 많지 않습니다. 그 이유로는 데이터의 축적, 경험, 전문인력이 부족하기 때문입니다. 연구소나 기업마다 그동안 실험으로 측정한 데이터를 다량 갖고 있으나 개인 노트나 보고서에 흩어져 있으며 이를 모으고 정리한 대형 데이터베이스를 구축한 곳이 적습니다.
원하는 소재개발에 적합한 데이터 수가 적으므로 MI 기술 예측정확도가 낮습니다. MI 기술을 실제로 다루어 보면 쓸만한 데이터가 많지 않으므로 제일 먼저 데이터베이스 구축 투자를 해야 합니다. 일본에서도 최대 화학기업인 미쓰비시케미칼을 비롯하여 데이터베이스 구축을 서두르는 기업들이 많아지고 있습니다.
다음으로 수행하고자 하는 분야별 데이터를 분석해서 전문지식을 기반으로 최적의 feature를 정하고 알고리즘을 만들거나 외부와 협력하여 예측과 설계를 해보는 노력이 필요합니다. 국내외 기업 모두 경험과 인력이 부족한 실정입니다. Feature와 알고리즘이 최적화되면 실증테스트를 반복해서 예측정확도를 높여야 합니다.
이는 장시간의 노력과 예산이 많이 듭니다. 이렇게 분야, 단계마다 각고의 노력이 요구되므로 더 각별한 노력과 숙성기간이 필요합니다.
MI 기술을 잘 활용하려면 IT 기업과의 협력이 중요합니다. 협력을 심층적으로 하려면 회사의 노하우나 비밀이 노출되고, IT 기업들이 이를 배우게 됩니다. IT 기업이 주도권을 갖게 되고 화학기업들은 하청업체로 전락할 수도 있습니다.
어려움이 있지만, 화학기업에 있어서 MI 연구는 피할 수 없는 대세입니다. 세계적으로 대부분 기업이 MI 기술 활용 초기 단계에 있습니다. 국내 기업들도 두려워하지 말고 자체 노력과 협력으로 역량을 쌓아 이른 시일 안에 MI 기술이 경영과 연구개발에 실질적으로 활용되기를 바랍니다.